
Which open-weight model should we choose? MoE? Q4?
Hasegawa from the Service Reliability Group (SRG) of the Media Management Division (@rarirureluis)is.
#SRGThe Service Reliability Group primarily provides comprehensive support for the infrastructure surrounding our media services, focusing on improving existing services, launching new ones, and contributing to open-source software (OSS).
This article explains technical terms such as open weights, quantization, and MoE to solve the complex problem of choosing a model and serve as a guide to help readers confidently select the AI model best suited to their hardware environment.
Qwen3.5 has good performance.Considering the uses of local LLMsWhat exactly is "open weight"?What is "quantization," and why is it necessary?Deciphering the naming conventions of quantizationCharacteristics and applications of each quantization level2-bit quantization (ultralightweight, experimental)3-bit quantization (lightweight and practical)4-bit quantization (balance-oriented, most popular)5-bit quantization (high quality, moderately large capacity)6bit quantization (high quality)8-bit quantization (almost original precision)What is MoE (Mixture of Experts)?What is Dynamic Quantization (Unsloth Dynamic)?Which quantization should I choose?summary
Qwen3.5 has good performance.
The Qwen3.5 is the latest open-weight model developed by Alibaba.
In my environment (DDR5-6400 256GB + RTX4090 Gen4 x16), running unsloth/Qwen3.5-35B-A3B-GGUF:UD-MXFP4_MOE achieves a speed of 143 tps with thinking enabled.

The Qwen3.5 boasts the highest benchmark scores among open-weight models.
Considering the uses of local LLMs
I use it in browser-use mode and with Brave Leo AI's BYOM model.
I was using Gemini 3.1 Pro for browser-use purposes, but I didn't notice any difference (subjectively).
In fact, thanks to the local environment, the response time has improved.
What exactly is "open weight"?
Recently, I've been hearing the term "open weight" more and more in the AI community.
Many people probably wonder, "How is this different from open source?"
Open weights are a form of modeling where only the weights of a pre-trained model and the minimum code required for inference are made public.
The training dataset, detailed training procedures, and hyperparameter details are not made public.
In short, a major feature of OpenWaite is that companies and researchers can download and run the "model itself" in their local environment.
There is no need to worry about the entered data being sent externally, and it is also possible to customize the system for your company through fine-tuning.
What is "quantization," and why is it necessary?
LLM parameters are typically represented using high-precision floating-point numbers such as bfloat16 and float32.
However, directly handling these numbers would require tens to hundreds of gigabytes of memory.
That's where the technology called "quantization" comes in.
Quantization is a technique that reduces file size and memory consumption by decreasing the number of bits used to represent each weight in a model.
For example, if you compress a value that is normally represented in 16 bits to 4 bits, you can reduce the file size to about one-quarter of its original size through simple calculation.
However, compressing information inevitably leads to a loss of some accuracy.
A smaller bit depth results in a lighter model, but it may also reduce the quality of the response.
This "size vs. quality" trade-off is the core of open-weight modeling.
Deciphering the naming conventions of quantization
UD-IQ2_XXSThe meaning of each symbol is as follows:
UD
Q
Q6
K
IQ2
XL
Characteristics and applications of each quantization level
The following is a list of the quantizations of the models we will be studying.
Here, we will use unsloth/Qwen3.5-35B-A3B-GGUF as an example.
2-bit quantization (ultralightweight, experimental)
| name | size |
|---|---|
| UD-IQ2_XXS | 9.76 GB |
| UD-Q2_K_XL | 12.9 GB |
This is the most aggressive compression method, representing each weight with only around 2 bits.
The ability to run large-scale models even in environments with limited VRAM is appealing, but it significantly impacts the quality of the response.
However, by combining this with dynamic quantization (UD), critical layers can be maintained at high precision, and quality exceeding expectations may be achieved.
Actual benchmarks have also reported that Unsloth's UD-Q2_K_XL outperforms standard 3-bit quantization (Q3_K_M) in several benchmarks.
UD-IQ2_XXS3-bit quantization (lightweight and practical)
| name | size |
|---|---|
| UD-IQ3_XXS | 14.1 GB |
| UD-IQ3_S | 15.2 GB |
| UD-Q3_K_M | 16.7 GB |
| UD-Q3_K_XL | 17.2 GB |
This quantization is intermediate between 2-bit and 4-bit.
UD-IQ3_XXSUD-Q3_K_MXL4-bit quantization (balance-oriented, most popular)
| name | size |
|---|---|
| UD-MXFP4_MOE | 19.5 GB |
| UD-Q4_K_M | 19.9 GB |
| UD-Q4_K_XL | 20.6 GB |
4-bit quantization is the most commonly used level because it offers a good balance between quality and size.
UD-Q4_K_XLWe keep the size down by assigning high-precision quantization such as Q5_K to important matrices, while using Q4_K for others.
UD-MXFP4_MOEMXFP4 (Microscaling FP4) is a standard developed by the Open Compute Project (OCP) and is also used in OpenAI's gpt-oss-120b.
It operates particularly efficiently on dedicated hardware (such as NVIDIA Blackwell generation).
5-bit quantization (high quality, moderately large capacity)
| name | size |
|---|---|
| UD-Q5_K_XL | 24.9 GB |
Select this option if you require higher quality than 4-bit.
Some experts believe that quantization using `int4` (4-bit integer) is sufficient, but in tasks requiring high precision, such as coding and logical reasoning, there are cases where the benefits of 5 bits or more can be felt.
6bit quantization (high quality)
| name | size |
|---|---|
| UD-Q6_K_S | 28.5 GB |
| UD-Q6_K_XL | 30.3 GB |
The quality degradation is barely noticeable.
UD-Q6_K_XL8-bit quantization (almost original precision)
| name | size |
|---|---|
| UD-Q8_K_XL | 38.7 GB |
8-bit is very close in quality to full precision (16-bit).
The increase in perplexity (the difficulty of predicting text) is almost zero, making it a good choice for research and verification purposes or in environments with ample VRAM.
What is MoE (Mixture of Experts)?
Along with quantization, the "MoE" architecture is also important.
MoE (Mixture of Experts) is a mechanism that incorporates multiple "expert" subnetworks within a model, activating only certain experts for each input token.
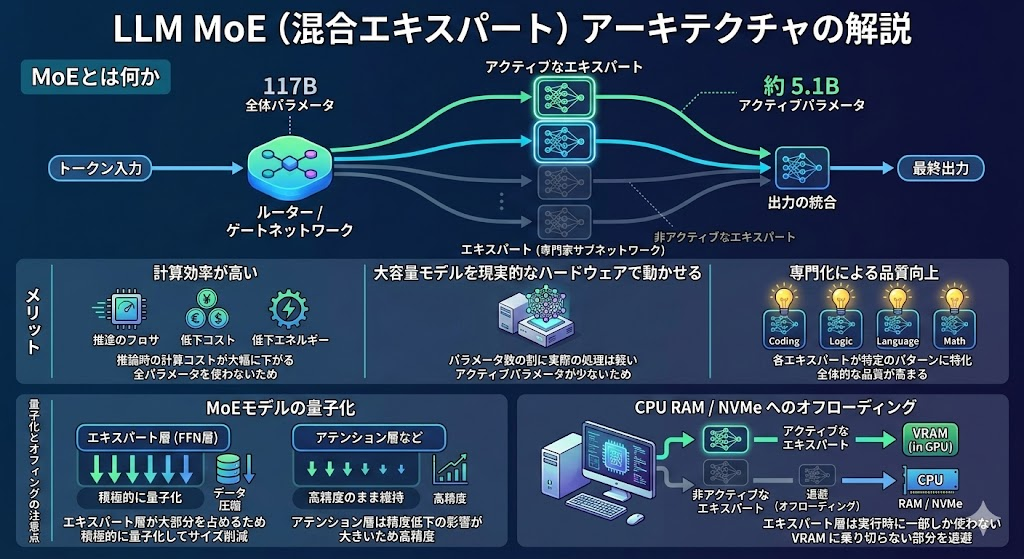
For example, even in a model with 120B parameters, in the case of the MoE architecture, the parameters actually used to process each token (active parameters) are only a fraction of the whole.
In the case of OpenAI's gpt-oss-120b, the total number of parameters is 117B, but the active parameters are approximately 5.1B.
The advantages of this system are as follows:
- High computational efficiency: Because not all parameters are used, the computational cost during inference is significantly reduced.
- Large-capacity models can run on realistic hardware: They have the characteristic of being "light in actual processing compared to the number of parameters."
- Quality improvement through specialization: When each expert specializes in a specific pattern, the overall quality improves.
There are some points to be aware of when quantizing MoE models.
Since the expert layer (FFN layer) accounts for the majority of the model's overall parameters, actively quantizing this layer is key to reducing its size.
On the other hand, layers such as the attention layer are more susceptible to accuracy degradation, so it is generally recommended to maintain high accuracy in those layers.
Another feature of the MoE model is that it is well-suited for "offloading" to the CPU and RAM.
Because the expert layer is only partially used at runtime, it's possible to run it while saving the portion that doesn't fit in VRAM to system RAM or NVMe.
What is Dynamic Quantization (Unsloth Dynamic)?
UD-Traditional uniform quantization compresses all layers with the same number of bits.
However, dynamic quantization analyzes in advance which layers of the model have a significant impact on the output, and automatically assigns high-priority layers to high precision (e.g., 8-bit or 16-bit) and low-priority layers to low precision (e.g., 2-bit or 3-bit).
This mechanism allows you to benefit from either "higher quality for the same file size" or "smaller file size for the same quality."
Dynamic quantization utilizes calibration data called an imatrix (Importance Matrix).
Unsloth uses its own calibration dataset optimized for conversation, coding, and inference tasks, which contributes to improved quality.
Actual benchmark results have shown that Unsloth's UD-IQ2_XXS has demonstrated higher task accuracy than other companies' IQ3_S in some cases, indicating that perplexity and KL divergence values alone may not be sufficient to accurately assess quality in real-world applications.
Q4_K_MWhich quantization should I choose?
Here's a summary of guidelines based on your hardware situation.
UD-IQ3_XXSUD-Q4_K_XLsummary
This article explained open weights, quantization, and MoE.
For systems with 16GB or more of VRAM, UD-IQ3_XXS or UD-Q4_K_XL are recommended.
MoE offers high computational efficiency and is well-suited for local inference. Achieve optimal AI model operation.
If you are interested in SRG, please contact us here.