
Starting Incident Management from Scratch - Introduction Part 2 -
This is Tanaka (@tako_sonomono) from the Service Reliability Group (SRG) of the Media Division.
#SRG (Service Reliability Group) is a group that provides comprehensive support for the infrastructure of our media services, mainly focusing on improving existing services, launching new ones, and contributing to open-source software.
IntroductionThe "resolution" required of the incident ownerOverview of the Incident LifecycleChallenges and countermeasures in the operational phase1. Location of Information Asset Management (Single Source of Truth)2. Designing Communication Channels3. The meaninglessness of ticket renewal and toilIn conclusion
Introduction
Last year's articleWe then discussed the establishment of "incident owners" and "incident commanders" in incident management, as well as the decision-making process for "triage."
These discussions focused on the "points" involved in initial incident response. This time, however, we will delve into the "line" leading to resolution—that is, the definition of the workflow—and the operational challenges involved in actually implementing it within an organization.
This article explains how incident owners should gain a high level of understanding of existing workflows, and discusses the communication design and documentation challenges they may face after deployment, incorporating SRE principles.
The "resolution" required of the incident owner
From an SRE perspective, one of the elements of effective incident management is a "Defined Process." Clear, pre-agreed procedures are essential to reduce the cognitive load during emergencies.
As a fundamental requirement, the incident owner must have a more accurate understanding of the existing workflows than anyone else in the organization. This is because the unique rules and collaborations specific to that business, which are not reflected in general frameworks, always have a historical and business context. Without understanding the whole picture, including these elements, the incident owner cannot guide the actions of their team members as a commander, nor can they provide a rational answer to the question of "why is that procedure necessary?"
To improve understanding and prevent reliance on individual expertise, we recommend first illustrating the workflow in your own words and documenting it as a Playbook.
Overview of the Incident Lifecycle
The incident flow varies depending on the size of the organization and the nature of the business. Taking the incident flow for a specific business at Amebalife as an example, and applying it to practical situations, it can be classified into the following 13 phases.
- Problem occurred: Initiation of user impact or system anomaly
- detectionAlert triggered, or inquiry received by CS.
- reactionAwareness by on-call staff and customer service representatives.
- Ticket: Creating a ticket using an incident management tool (Jira/ServiceNow, etc.)
- TriageIdentifying the scope of impact, determining SEV (severity), and establishing a system.
- primary report: First report via communication tool (Slack, etc.)
- User Communication: Incident report (status page updated, announcement posted)
- Recovery ResponseInvestigation, Fix creation, Deployment
- Provisional restoration: Service level has returned to an acceptable range.
- User CommunicationRecovery report (status page updated, announcement posted)
- PostmortemReview, RCA (Root Cause Analysis)
- Permanent solutionImplementation of measures to prevent recurrence
- CloseTicket completed
What is clear from this flow is that incident response is not limited to the engineering domain.
In particular, collaboration with CS, public relations, and the business side in phases 7 and 10 is just as important as system recovery from the perspective of "service reliability from the user's point of view."
*Workflow actually created
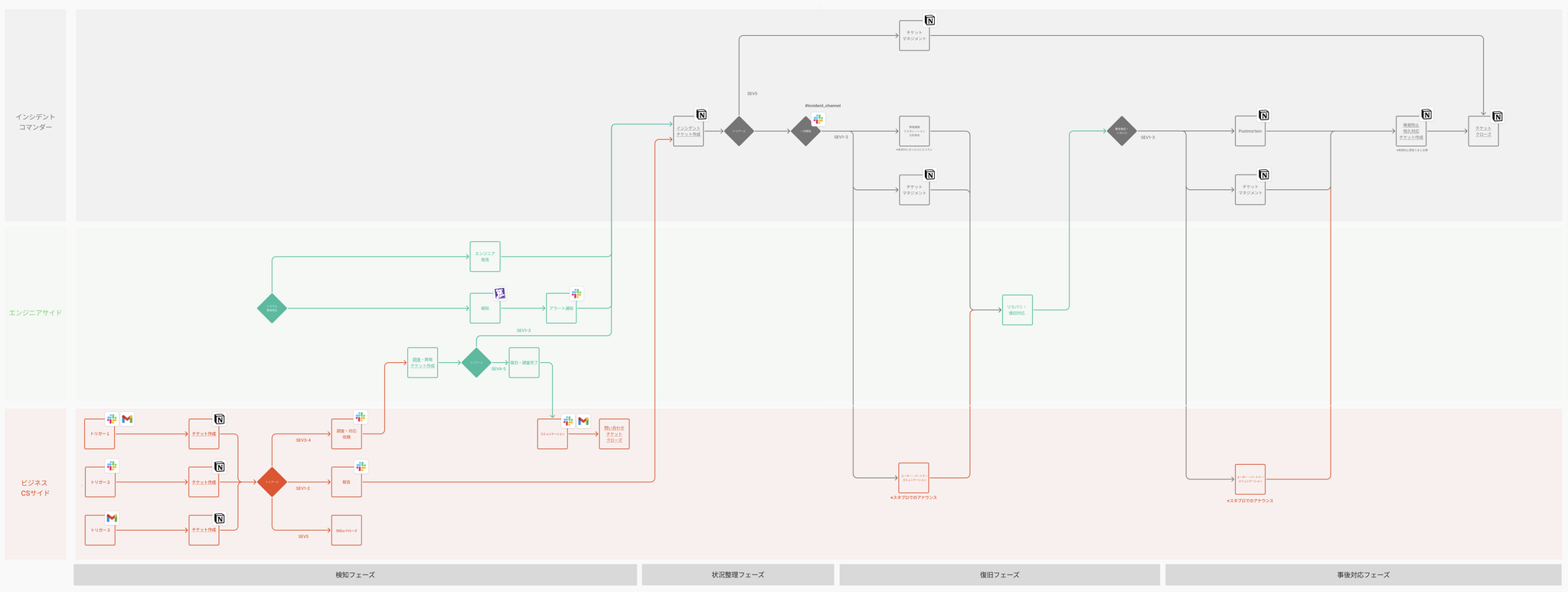
It is recommended to create separate flows for each segment (IC/Engineer/Business).
Challenges and countermeasures in the operational phase
Even with an ideal workflow defined, the unpredictable element of "human interaction" becomes a bottleneck in actual operation. This document describes the major challenges faced after implementation and how to address them.
1. Location of Information Asset Management (Single Source of Truth)
While you can use any tool to manage documents such as operational flows, tips, and contact lists, the important thing is discoverability. These documents must be placed in a location where they can be easily accessed in an emergency.
2. Designing Communication Channels
Where to hold discussions (War Room) during incident response involves a trade-off between information transparency and catch-up costs.
- Ticket contents: High record-keeping but lacks immediacy.
- Slack threads: Convenient, but readability decreases significantly as the amount of information increases.
- Dedicated Slack channel (Spot): Recommended
For incidents with a high SEV (Severity Effect Value), a dedicated Spot channel should be created to consolidate information. This is recommended from a "cognitive load" perspective.
Slack's threaded discussion format makes it difficult to follow the timeline, increasing the catch-up cost for supporters and decision-makers who join later. Dedicated channels allow for the isolation of information noise and facilitate integration with bots such as ChatOps.
3. The meaninglessness of ticket renewal and toil
Many organizations encounter the situation where they "don't have time to update tickets while responding to an incident." However, delays in ticket updates lead to delays in sharing the situation with stakeholders, resulting in an increase in individual inquiries (interrupted tasks) to engineers.
Furthermore, the quality of future data analysis and postmortem analysis will also decline.
Forcing complete manual synchronization to address this challenge is not realistic.
This should be considered a type of toil that SREs should eliminate.
Currently, we are promoting the establishment of a workflow for "automatic summary generation and ticket updates from Slack interactions and conversation logs."
In conclusion
This time, we have summarized the definition of processes and operational challenges in incident management.
When promoting incident management, there's a tendency to prioritize tool selection, but the essence lies in whether the incident owner can accurately grasp the "as-is" situation and identify where the bottlenecks are. Based on the premise that "humans cannot autonomously perform operations that involve organizing information," the focus of future incident management will be on how to ensure the reliability of processes by utilizing systems and AI.
If you are interested in SRG, please contact us here.